
NetOrca approach to Automation
Gaps in the journey to Infrastructure As Code.
From our experiences working with large enterprises we continue to see common challenges for Infrastructure teams and developers alike when making the journey to Infrastructure Automation.
Many of these challenges arise from the size, change management and processes that have been in place for considerable time at large enterprises, as opposed to younger, smaller start-ups.
Current Status
We identify two roles that tend to stand out in any attempt to Automate Infrastructure Changes:
Consumers
The teams that consume the infrastructure resources to deploy business solutions.
Challenges to Consumers
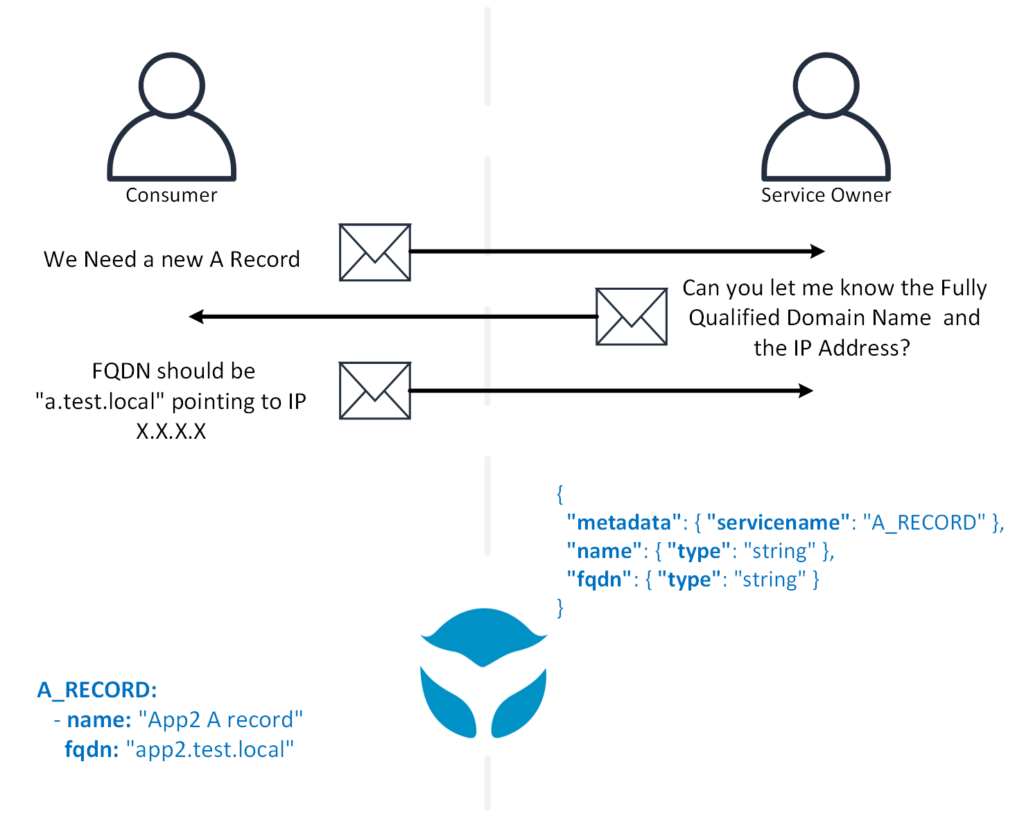
The information about requests for infrastructure is spread across multiple platforms. This does not allow for quick verification of what is the desired state, and the actual state of the infrastrucutre.
Developers spend time to learn the different requests that need to be done, monitor the progress, and keep track of which requests are for which applications. This is all knowledge and administrative tasks that are not directly adding value to the business offering.
The desired state for all the infrastructure cannot be easily captured in Version Control Systems.[1]
Service Owners
The teams who manage infrastructure. It is this team that makes changes to the infrastructure.
Challenges to Service Owners
Sometimes different teams end up developing different front-ends for users to use, leading to inconsistency in the way someone would request a change and duplicated work inside the same company.
If workflow solutions (ex: ServiceNow) are used, then development needs to be done to develop new workflows which needs to be done by engineers familiar with that product.
If a custom solution is developed internally, engineers need to spend a large amount of time designing for all the possible scenarios of problems that can occur. All this is time not spent on developing business offerings directly.
Developers requesting a change need to be aware of whether it has been automated or not.
Where approvals and auditing are required, bespoke integrations with existing internal platforms have to be developed.
The NetOrca approach
Offer and consume services
In NetOrca, we think of everything as a service being offered by one team and used by anyone. Examples:
- A service that offers DNS records
- A service that offers a VM.
With this approach:
- Changes to the infrastructure are very well-defined and repeatable. The consumer knows what information to give and what to expect when the work is completed.
- Lends itself well to automation, and it guides the teams to define the changes they offer into well-defined services.
- Agnostic of how well automated the change is. As you will see, this could all be used with manual changes or automated changes, and the consumer would not need to know the difference.
- Easy to audit what configuration an App needs, or how many services are in use etc.
{
"metadata": {
"servicename": "A_RECORD"
},
"name": {
"type": "string"
},
"fqdn": {
"title": "Fully Qualified Domain Name",
"type": "string"
}
} A_RECORD:
- name: "app A record"
fqdn: "a.test.local"Declare what you offer, declare what you consume
In NetOrca Creating, Modifying or Deleting a service are done declaratively.
As a Service Owner you write a json schema that defines what inputs are required for a service, and publish it for customers to consume. As a Consumer, you declare in a JSON or YAML file all the services that your application requires.
This approach carries a number of advantages:
- All the configuration required to deploy an application is in a single location/file, making it easier to capture in version control systems.
- The inputs required to carry out a change on the infrastructure are captured and ready for the service owner to use, either through automation or manual changes.
- Integration with GitOps is very intuitive. (Refer to integration section)
Least information from consumer
Customers should be expected to input the least information possible and just the information that they are in control of. All other information should come from templates or dependent services
NetOrca supports services depending on each other, thus information can be cascaded from one service to another. Ex: A request for a load balancer depends on VMs already being deployed. NetOrca can be used to retrieve the IP address of the VM service instance required for the configuration of the load balancer.
We feel that this is an improvement on current approaches because:
- This would be less onerous on the developer to learn how things should be configured.
- Less risk of human error when information is gathered from one place and entered somewhere else
- Leads team to build services that are well defined, with dependencies that are clear.
- Allows for very strict validation of requests and very quick feedback to customers if anything is wrong with a request, even before an engineer has ever looked at the request.
{
"metadata": {
"servicename": "A_RECORD",
"service_dependancies": [
"VM"
],
},
"name": {
"type": "string"
},
"fqdn": {
"title": "Fully Qualified Domain Name",
"type": "string"
}
} VM:
- name: "CoreVM_1"
cpu: 4
memory: 8
A_RECORD:
- name: "app A record"
fqdn: "a.test.local"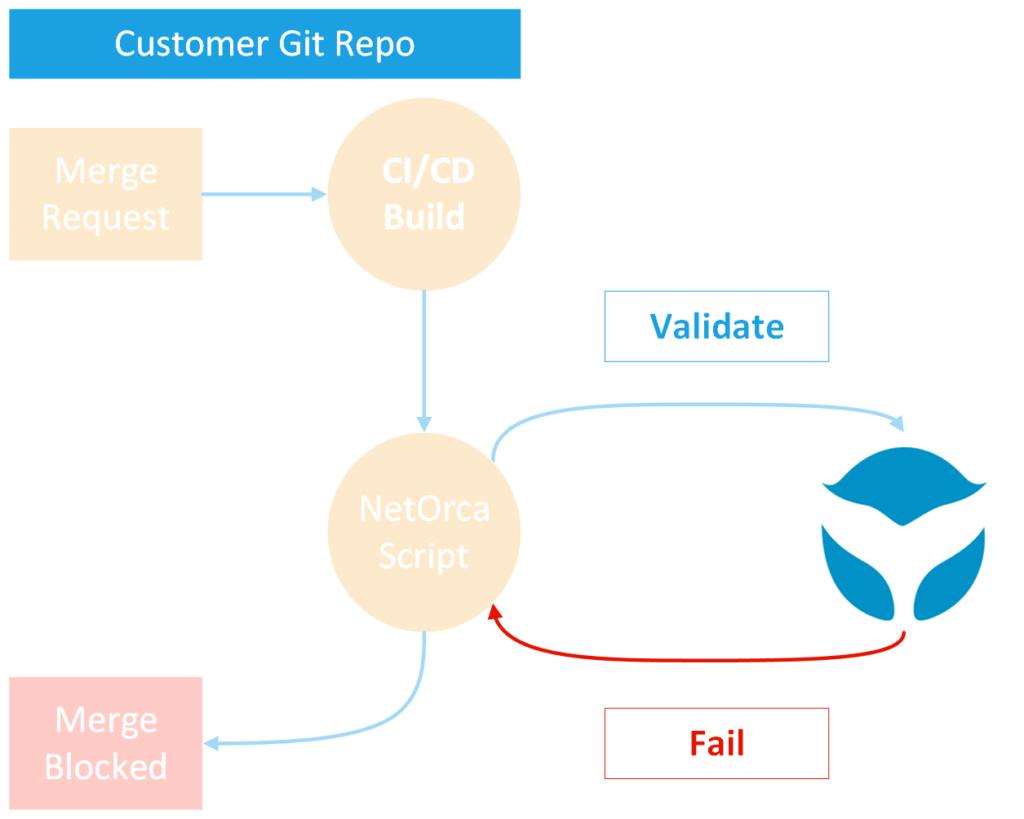
Validate early
Since the requirements for a service should be very well defined, NetOrca is able to offer validation API endpoints that check and incoming request from a consumer and informs them whether it adheres to all the requirements.
In this way:
- Human validation may not even be required if it can all be captured in the JSONschema
- If human validation/approval is required, a lot of simple mistakes can be captured earlier, saving time.
- Consumers get immediate feedback on their changes, without having to await human feedback.
- Integrates well with CI/CD pipeline to validate branches.
Version everything
For services that are offered, a version number is used to keep track of the information requested from a consumer of that service. This allows us to update services offered and keep track of which version of the service someone consumed.
For service requests, versioning lets us keep track of where/when a change was done, and which changes already be implemented and which have not.
- This would be less onerous on the developer to learn how things should be configured.
- Less risk of human error when information is gathered from one place and entered somewhere else
- Leads team to build services that are well defined, with dependencies that are clear.
- Allows for very strict validation of requests and very quick feedback to customers if anything is wrong with a request, even before an engineer has ever looked at the request.
{
"metadata": {
"servicename": "A_RECORD",
"schemaversion": "1.0.1",
"owningteam": "networkautomation",
"service_dependancies": [
"VM"
],
},
"name": {
"type": "string"
},
"fqdn": {
"title": "Fully Qualified Domain Name",
"type": "string"
}
}